sse2string — funkcje string.h zaprogramowane z użyciem instrukcji SSE2
| Dodane: | 31.08.2007 |
|---|---|
| Aktualizacja: | 31.05.2008 |
| Autor: | Wojciech Muła, wojciech_mula@poczta.onet.pl |
Spis treści
Wprowadzenie
Biblioteka sse2string to implementacje kilku funkcji zdefiniowanych w string.h, zaprogramowane z użyciem rozkazów SSE2 (tj. intelowskie rozszerzenia SIMD wprowadzone od Pentium IV).
Obecnie dostępne są następujące bezpośrednie zamienniki standardowych funkcji:
- sse2_strlen
- sse2_strchr
- sse2_strrchr
- sse2_strcmp
Oraz funkcje szybsze, zakładające wyrównanie wskaźników do granicy 16 bajtów i nie posiadający zabezpieczeń przed odczytem spoza przestrzeni adresowej procesu:
- sse2_strlen_unsafe
- sse2_strchr_unsafe
- sse2_strrchr_unsafe
- sse2_strcmp_unsafe
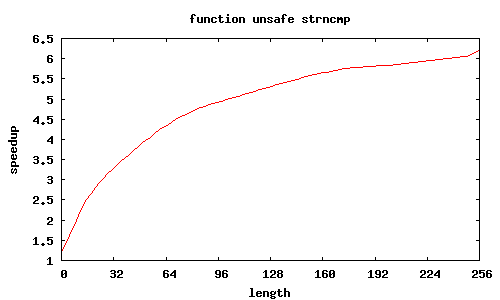
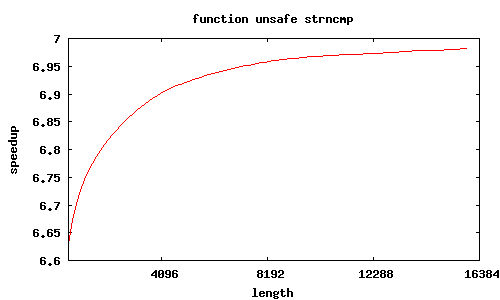
- sse2_strncmp_unsafe
Testy wydajności (1.09.2007)
Testy przeprowadzone na komputerze z procesorem Pentium M:
Na osobnej stronie dostępne są również testy wstępnych wersji funkcji strlen_unsafe, strcmp_unsafe, strchr_unsafe przeprowadzone na kilku różnych procesorach.
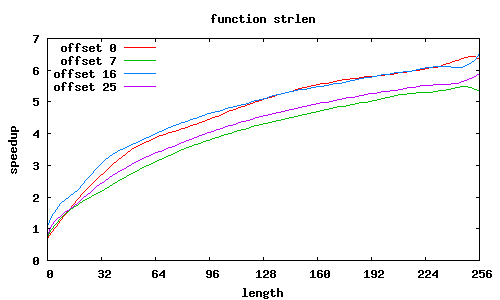
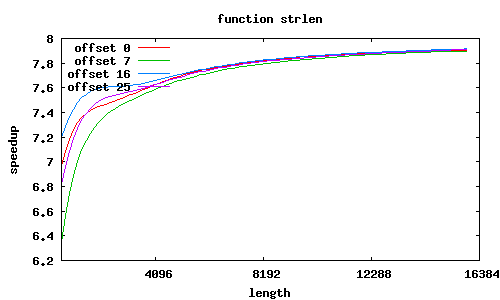
strlen
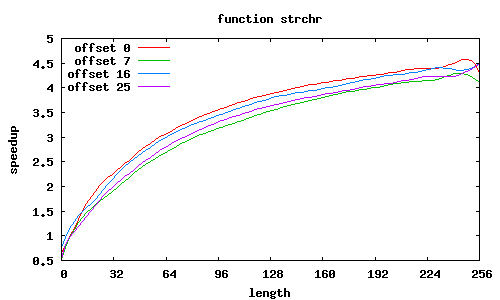
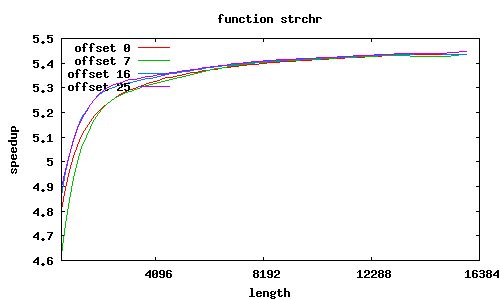
strchr
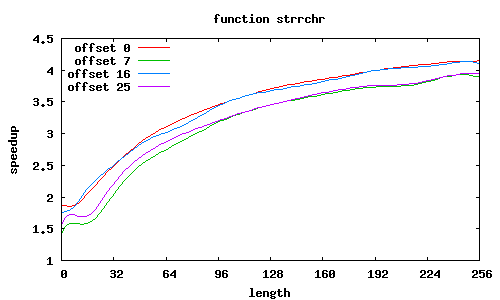
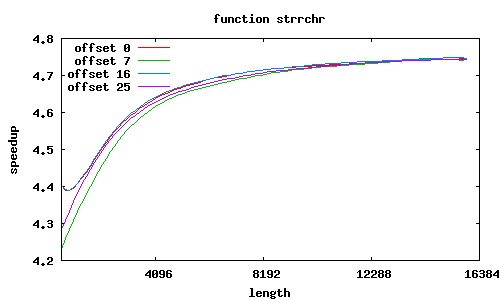
strrchr
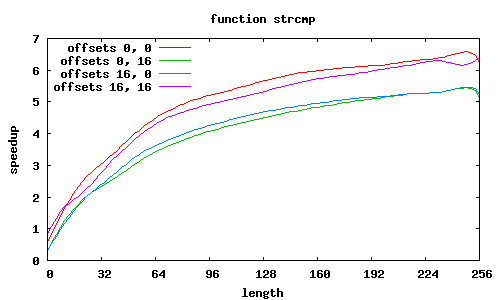
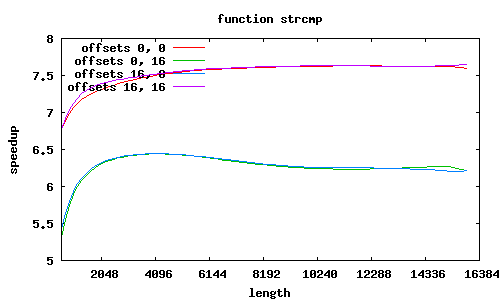
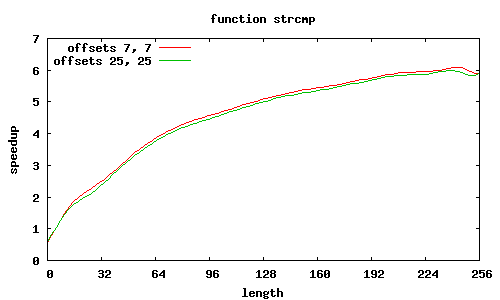
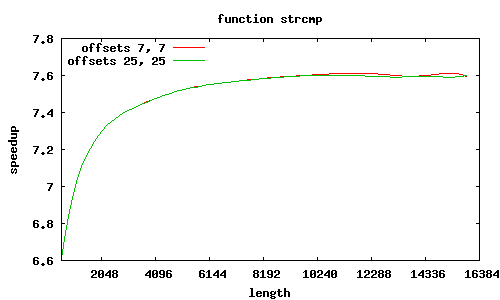
strcmp
Funkcja sse2_strcmp rozpoznaje kilka przypadków wyrównania łańcuchów względem początku strony, o czym decyduje 12 najmłodszych bitów adresów.
Adresy wyrównane
Jeden adres niewyrównany
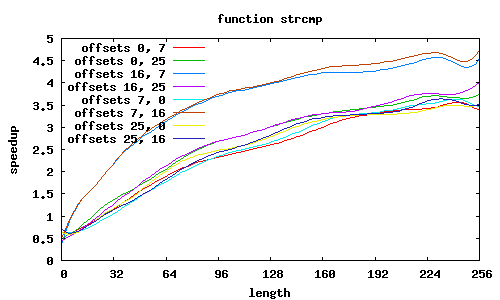
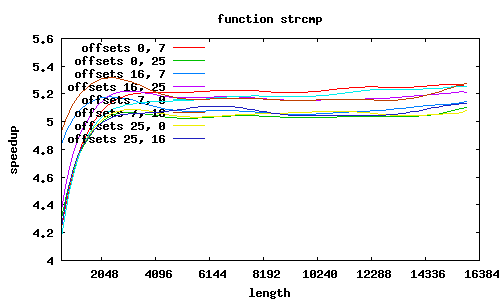
Adresy niewyrównane
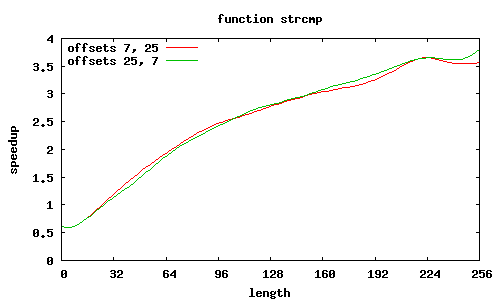
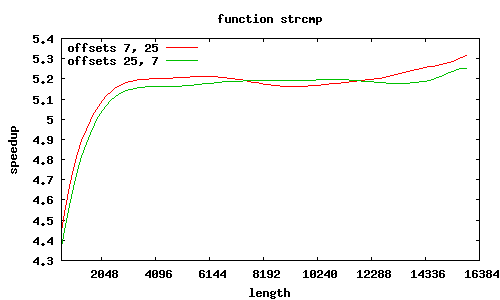
Adresy niewyrównane, ale przesunięcia równe
strncmp_unsafe
Dyskusja wyników
Porównanie było wykonywane względem standardowych funkcji z GNU lib C, zoptymalizowanych dla i686.
Rozkazy SSE2 przetwarzają równocześnie 16 bajtów, dzięki czemu możliwe jest uzyskanie znacznego przyspieszenia; jest ono tym większe, im przetwarza się więcej danych.
Niestety dla niewielkiej ilości danych (kilka-kilkanaście znaków) czas wykonania procedur zostaje zdominowany przez fragmenty inicjujące oraz zbierające wyniki — wykonywane tylko raz na wywołania funkcji — i w takich przypadkach obserwuje się spowolnienie (nieraz znaczące) w stosunku do standardowych procedur. Nie sposób tego ominąć.
Co jeszcze wpływa na przyspieszenie? W SSE2 zakłada się, że dane są wyrównane do granicy 16 bajtów, i dedykowany rozkaz MOVAPS akceptuje tylko takie adresy. Możliwy jest co prawda odczyt danych niewyrównanych (rozkaz MOVUPS), jednak trwa dłużej. Dlatego procedury muszą „radzić sobie” z niewyrównanymi adresami, przeprowadzając dodatkowe testy i używając specjalizowanych ścieżek wykonania; jest to szczególnie widoczne w procedurze sse2_strcmp, w której dla łańcuchów niewyrównanych przyspieszenie znacząco spada; jeśli jednak przesunięcia obu niewyrównanych łańcuchów względem stron są równe, to można całkiem zgrabnie sobie poradzić.
Ponadto, ponieważ procedury w większości przypadków próbują czytać od razu 32 bajty na iterację (co daje dodatkowe przyspieszenie), należało zabezpieczyć się przed przekroczeniem przestrzeni adresowej procesu, a to również trochę kosztuje.
Aby uzyskać maksimum wydajności należy stosować funkcje *_unsafe, które — jak już wspomniano — zakładają wyrównanie adresów oraz nie dbają o potencjalne przekroczenie przestrzeni adresowej, dzięki czemu odpada cały narzut dodatkowych testów. Aby te funkcje można było bezpiecznie stosować należy stworzyć odpowiednie środowisko, tj zagwarantować dwie rzeczy: wyrównanie wskaźników oraz nieco większą przestrzeń adresową o przynajmniej 32 bajty (w praktyce to będzie rozmiar strony, czyli zwykle 4kB).
Wyrównanie adresów
Kompilator gcc umożliwia deklarowanie wyrównanych danych, np.:
char text[] __attribute__((aligned(16))) = "text";
jednak wygodniej jest utworzyć nowy typ danych:
typedef char __attribute__((aligned(16))) pchar[]; pchar text = "text";
Jeśli chodzi o dynamiczną alokację pamięci, to funkcja malloc z GNU Lib C na maszynach 64-bitowych zawsze rezerwuje bloki pamięci o adresach wyrównanych do granicy 16 bajtów zatem problemu nie ma.
Natomiast na maszynach 32-bitowych wyrównanie jest do 8 bajtów i wówczas można wykorzystać funkcję memalign (z malloc.h) lub posix_memalign (ze stdlib.h):
#include <stdlib.h> #include <malloc.h> char* x; x = memalign(16, block_size); posix_memalign((void*)&x, 16, block_size);
Zwiększanie przestrzeni adresowej (wstępna wersja)
W GNU Lib C służy do tego funkcja brk (unistd.h), która powiększa segment danych.
Co dalej? [31.05.2008] 
Widzę jeszcze przynajmniej dwa całkiem sensowne zastosowania dla instrukcji SSE2:
- porównanie łańcuchów zakodowanych w ASCII bez uwzględnienia wielkości liter.
- szybkie stwierdzanie, czy dwa krótkie łańcuchy (16..32 znaki) są identyczne.
Ponadto Intel zapowiada SSE4.2, wprowadzające kilka „smakowitych” instrukcji (STTNI) ułatwiających realizację funkcji łańcuchowych.
Początkowo wydawało mi się, że również realizacja strlen dzięki pojawieniu się w SSE4.1 rozkazu PTEST będzie wydajniejsza, jednak jak wykazują moje testy — niestety kod jest wolniejszy niż przedstawiony tutaj.
Z kolei dzięki rozkazowi MPSADBW (gołym okiem widać, że zaprojektowanemu pod kątem kodowania wideo), możliwa stała się całkiem wydajna implementacja wyszukiwania tekstu — modyfikacja algorytmu Karpa-Rabina.
Podziękowania
Biblioteka sse2string z całą pewnością nie powstałaby bez pomocy dwóch osób:
- Kuba Nadolny — udostępnił konto shellowe na porządnej maszynie oraz zainstalował niezbędne oprogramowanie, dzięki czemu mogłem przetestować wszystkie procedury.
- Piotrek Wyderski — bez bardzo pouczające i owocnej dyskusji na pl.comp.lang.c (początkowa wiadomość o M-ID slrnfbr98k.3e5.wojciech_mula@cat.tac), kod nie wyglądałby tak, jak teraz; szczególnie cennym okazał się sposób na pominięcie jednego roazkazu pmovmaskb w rozwiniętej pętli.
Dziękuję także Sewerynowi Habdank-Wojewódzkiemu i Łukaszowi Krotowskiemu, którzy przetestowali pierwsze wersje tych procedur.
Licencja
Biblioteka sse2string jest objęta licencją BSD.
Źródła
Źródła dostępne są na githubie.
Historia zmian
- 4.09.2007 — nieznacznie przyspieszona funkcja sse2_strncmp_unsafe
- 1.09.2007 — pierwsza wersja biblioteki
- xx-14.08.2007 — pierwsze wersje xxx_unsafe
Kompilacja
Należy przejść do katalogu src i wykonać make albo make imul albo make sse3.
Polecenia make, make imul i make sse3 tworzą tę samą bibliotekę, lecz ustawiają różne flagi kompilacji dla funkcji sse2_strchr i sse2_strrchr, które wpływają na efektywność fragmentu procedury odpowiedzialnego za powielanie bajtu:
- imul — wykorzystywany jest rozkaz IMUL (mnożenie) i warto go wykorzystać, jeśli procesor ma niskie opóźnienie dla tego rozkazu;
- sse3 — wykorzystywany jest rozkaz PSHUFB.