Use AVX512 to calculate binomial coefficient
| Author: | Wojciech Muła |
|---|---|
| Added on: | 2020-03-21 |
Contents
Introduction
The value of binomial coefficient kovern can be expressed as n!/(k! ⋅ (n − k)!). This can be simplified to [(n − p) ⋅ (n − p + 1) ⋅ … ⋅ (n)]/p!, where p = max(k, n − k). Daniel Lemire showed in article Fast divisionless computation of binomial coefficients how efficiently evaluate the latter expression.
Can SIMD instructions be utilized to get binomial coefficients? I wish I could write "yes, they can", but the answer is not optimistic. SIMD instructions can be used to perform in parallel several pairs of multiplications, however it's a quest to properly setup registers and deal with different numbers of arguments that depend on the n and k. That's the first option, which I didn't check.
What I checked and described here is utilization of AVX512 with a different numeric system. An important fact is that calculation of binomial coefficients involves only multiplication and (integer) division.
We do know that all natural numbers can be factorized, i.e. represent as a product of prime numbers raised to some non-negative powers. For instance, 20200320 is equal to 27 ⋅ 33 ⋅ 5 ⋅ 7 ⋅ 167, similarly 7812 is 22 ⋅ 32 ⋅ 7 ⋅ 31. Now a product of two factored numbers can be calculated by adding the exponents of corresponding primes. For example 20200320 ⋅ 7812 = 2(7 + 2) ⋅ 3(2 + 3) ⋅ 5 ⋅ 7(1 + 1) ⋅ 31 ⋅ 167 = 29 ⋅ 35 ⋅ 5 ⋅ 62 ⋅ 31 ⋅ 167. Likewise, division requires subtraction of exponents.
The core idea is to represent input integers as factored numbers. We setup the fixed number of primes and then operate only on exponents. We make sure that exponents fit in 8-bit values, thus in case of AVX512 we have 64-element products. With such representation, the vector addition and subtraction instructions are sufficient to calculate binomial coefficients.
So far everything might sounds nice, but unfortunately there are some serious problems:
- Factorization is not cheap, we must cache exponents. Since we must cache intermediate values, why not pre-calculate binomial coefficients?
- Getting back from factorized representation is also not cheap. It requires multiplication and getting integer powers (also multiplication).
- To my surprise, the range of inputs covered by a SIMD-ized algorithm is smaller than a scalar version. I supposed that cancellation of primes present in both nominator and denominator would be beneficial.
SIMD algorithms
Reference scalar algorithm
uint64_t binom_scalar(uint64_t n, uint64_t k) { assert(n > 1); assert(k > 1); assert(k < n); const uint64_t p = std::min(k, n - k); uint64_t num = 1; uint64_t denom = 1; for (uint64_t i=0; i < p; i++) { num *= n - p + (i + 1); denom *= (i + 1); } return num / denom; }
AVX512 algorithm 1
Below is the AVX512 procedure, which is a direct translation of the scalar one.
uint64_t avx512_binom_scalar(uint64_t n, uint64_t k) { assert(n > 1); assert(k > 1); assert(k < n); const uint64_t p = std::min(k, n - k); __m512i vnum = _mm512_setzero_si512(); __m512i vdenom = _mm512_setzero_si512(); // multiply for (uint64_t i=0; i < p; i++) { const uint64_t num_coef = n - p + (i + 1); const uint64_t denom_coef = i + 1; vnum = _mm512_add_epi8(vnum, _mm512_loadu_si512((const __m512i*)(avx512binom::numbers[num_coef - 1]))); vdenom = _mm512_add_epi8(vdenom, _mm512_loadu_si512((const __m512i*)(avx512binom::numbers[denom_coef - 1]))); } // divide num/denom const __m512i tmp = _mm512_sub_epi8(vnum, vdenom); int8_t coef[64]; _mm512_store_si512((__m512i*)coef, tmp); // get back from the product of factorials into the integer domain uint64_t num = 1; uint64_t denom = 1; for (int i=0; i < 64; i++) { if (coef[i] > 0) num *= int_power(avx512binom::primes[i], coef[i]); else if (coef[i] < 0) denom *= int_power(avx512binom::primes[i], -coef[i]); } return num / denom; }
There are three major stages of the procedure:
- Calculation of the nominator and denominator, which requires fetching the pre-calculated exponents and summing them up using vector additions (_mm512_add_epi8).
- Division the nominator by denominator: just a vector subtraction (_mm512_sub_epi8).
- Get back from the product world into a single, 64-bit value. At this stage we have exponents either positive or negative. We separately calculate products for powers with negative and positive exponents and finally divide them.
AVX512 algorithm 2
Instead of pre-calculating factors for separate numbers, we can pre-calculate valeues of factorials (n!) and then use the initial fromula n!/(k! ⋅ (n − k)!). This requires only three fetches from memory, one vector addition and one vector subtraction.
uint64_t avx512_binom_scalar2(uint64_t n, uint64_t k) { assert(n > 1); assert(n < avx512binom::factorials_count); assert(k > 1); assert(k < avx512binom::factorials_count); assert(k < n); // n! __m512i fn = _mm512_loadu_si512((const __m512i*)(avx512binom::factorials[n])); // k! __m512i fk = _mm512_loadu_si512((const __m512i*)(avx512binom::factorials[k])); // (n - k)! __m512i fnk = _mm512_loadu_si512((const __m512i*)(avx512binom::factorials[n - k])); const __m512i vdenom = _mm512_add_epi8(fk, fnk); // k! * (n -k)! const __m512i tmp = _mm512_sub_epi8(fn, vdenom); // n! / ... int8_t coef[64]; _mm512_store_si512((__m512i*)coef, tmp); // get back from the product of factorials into the integer domain uint64_t num = 1; uint64_t denom = 1; for (int i=0; i < 64; i++) { if (coef[i] > 0) num *= int_power(avx512binom::primes[i], coef[i]); else if (coef[i] < 0) denom *= int_power(avx512binom::primes[i], -coef[i]); } return num / denom; }
This algorithm has one disadvantage: if we want to keep 8-bit exponents, the maximum value of exponent must be 63 as we do addition (so maximum would be 126).
Conclusions
While using AVX512 for this particular problem is highly inefficient and should be seen as an another weird use of SIMD, I do see a potential in large number multiplication.
For instance, if we have 128-bit numbers (16 bytes), the maximum value we can store is 2128 = 340282366920938463463374607431768211456. For factorized numbers we have 263 ⋅ 363 ⋅ 563 ⋅ 763 ⋅ 1163 ⋅ 1363 ⋅ 1763 ⋅ 1963 ⋅ 2363 ⋅ 2963 ⋅ 3163 ⋅ 3763 ⋅ 4163 ⋅ 4363 ⋅ 4763 ⋅ 5363 which is equal to:
2106726749334627350410628336115108697819507335706618403749027881 2918394460268566776926380571111752890122643190700770060699783710 0716838823029246452041344623890055565783403481861108977019331615 6909731529888223855956433183828393250309212616147571581484564238 0237991257108001969729559578902233038349381599595956237440142301 3595617075194641095023929988757660189907907436397521378410511648 0286463051236043942875871601624370376551655597122336338503038580 1300414948823558420320766406337364057856589827163146948392471915 2652805281907763353798434051310077270343189837263486549214122909 5472375766950871636704350899997482923539727630775043744427079847 3424551608217733700677412073382604713005461932070101186771762018 6837579867388226291033932718873308410698880975732815838467343784 8092522652538644761406947635955468146408066577334997222833964147 2390038787843042373358959310849844548045327894586272083322892151 0664878362178007434660480703738106236096755828750572888785616516 7049890972526424436366899381698996870420219988594467185739732834 0594607365945761851136158715020463884569489725070091862870680087 9496156990791363678761335474021351083052803423877056618598763177 4571506135150170000000000000000000000000000000000000000000000000 00000000000000
Comparison of inputs ranges
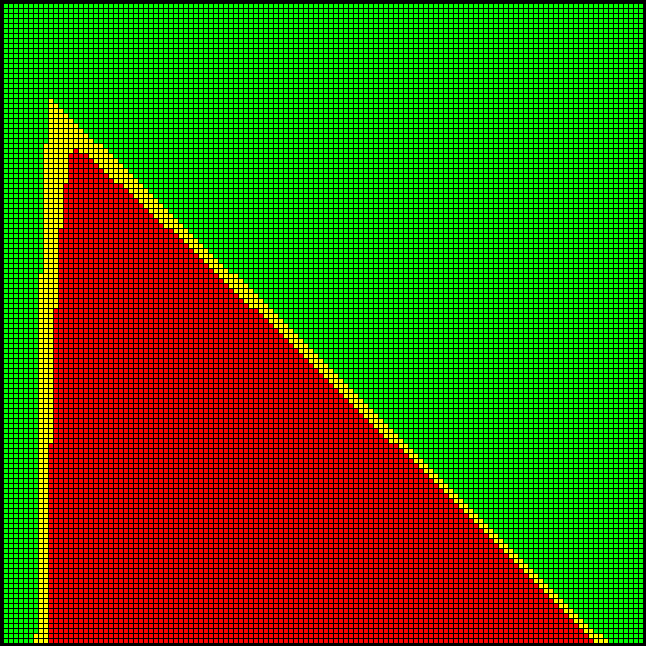
Following picture show results for all combinations of n and k in range 1…128, where:
- red cell: both the scalar and AVX512 procedures overflow on 64-bit operations;
- green cell: both produces yield valid results;
- yellow cell: only the scalar procedure does not overflow.
Source code
All code is available on github.