AVX512 implementation of JPEG zigzag transformation
| Author: | Wojciech Muła |
|---|---|
| Added on: | 2018-05-13 |
| Updated on: | 2018-11-04 (added 16bit-array shuffling) |
Introduction
One of steps in JPEG compression is zigzag transformation which linearises pixels from 8x8 block into 64-byte array. It's possible to vectorize this transformation. This short text shows SSE implementation, then its translation into AVX512BW instruction set, and finally AVX512VBMI code.
The order of items in a block after transformation is shown below:
[ 0 1 5 6 14 15 27 28 ] [ 2 4 7 13 16 26 29 42 ] [ 3 8 12 17 25 30 41 43 ] [ 9 11 18 24 31 40 44 53 ] [ 10 19 23 32 39 45 52 54 ] [ 20 22 33 38 46 51 55 60 ] [ 21 34 37 47 50 56 59 61 ] [ 35 36 48 49 57 58 62 63 ]
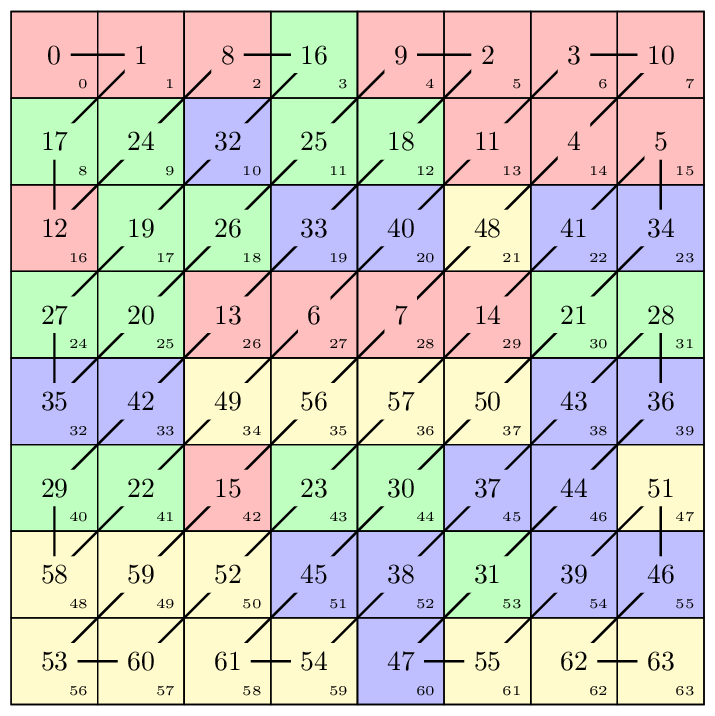
Shuffling 8-bit arrays
Scalar implementation
Following procedure uses auxiliary table to pick proper pixels.
uint8_t zigzag_shuffle[64] = { 0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5, 12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28, 35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51, 58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63 }; void jpeg_zigzag_scalar(const uint8_t* in, uint8_t* out) { for (int i=0; i < 64; i++) { unsigned index = zigzag_shuffle[i]; out[i] = in[index]; } }
It is compiled into a few instructions:
jpeg_zigzag_scalar: leaq zigzag_shuffle(%rip), %rcx xorl %eax, %eax ; eax is 'i' .L2: movzbl (%rcx,%rax), %edx ; fetch index movzbl (%rdi,%rdx), %edx ; fetch byte from in[index] movb %dl, (%rsi,%rax) ; store at out[i] addq $1, %rax cmpq $64, %rax jne .L2 rep ret
SSE implementation
Since SSE registers have 128 bits, only four registers are needed to hold the whole block; each register gets two 8-pixels rows. Let's label these registers with A, B, C and D:
A = [ 0| 1| 5| 6|14|15|27|28| 2| 4| 7|13|16|26|29|42]
B = [ 3| 8|12|17|25|30|41|43| 9|11|18|24|31|40|44|53]
C = [10|19|23|32|39|45|52|54|20|22|33|38|46|51|55|60]
D = [21|34|37|47|50|56|59|61|35|36|48|49|57|58|62|63]
</pre>Then, the block after transformation is formed with following indices from the registers:
[ 0A 1A 8A 16B 9A 2A 3A 10A] [17B 24B 32C 25B 18B 11A 4A 5A] [12A 19B 26B 33C 40C 48D 41C 34C] [27B 20B 13A 6A 7A 14A 21B 28B] [35C 42C 49D 56D 57D 50D 43C 36C] [29B 22B 15A 23B 30B 37C 44C 51D] [58D 59D 52D 45C 38C 31B 39C 46C] [53D 60D 61D 54D 47C 55D 62D 63D]
The algorithm produces two 8-pixel lines in a single step. In each step similar operations are performed:
- Bytes in registers are shuffled to desired position using instruction pshufb (_mm_shuffle_epi8).
- All these shuffled vectors are or'ed together.
To build rows 0 & 1 we need registers A, B, C; rows 2 & 3 and 4 & 5 use data from all registers; rows 6 & 7 use data from B, C and D.
The instruction pshufb either puts a byte at given index or zeroes the destination byte, thanks to that masking is done at no cost. Please also note that in a few cases just single byte from given vector is needed. Then the pair of instructions pextb (_mm_extract_epi8) and pinsb (_mm_insert_epi8) is used.
Sample implementation:
void jpeg_zigzag_sse(const uint8_t* in, uint8_t* out) { const __m128i A = _mm_loadu_si128((const __m128i*)(in + 0*16)); const __m128i B = _mm_loadu_si128((const __m128i*)(in + 1*16)); const __m128i C = _mm_loadu_si128((const __m128i*)(in + 2*16)); const __m128i D = _mm_loadu_si128((const __m128i*)(in + 3*16)); // row0 = [ A0| A1| A8| B0| A9| A2| A3|A10| B1| B8| C0| B9| B2|A11| A4| A5] const __m128i row0_A = _mm_shuffle_epi8(A, _mm_setr_epi8(0, 1, 8, -1, 9, 2, 3,10, -1, -1, -1, -1, -1,11, 4, 5)); const __m128i row0_B = _mm_shuffle_epi8(B, _mm_setr_epi8(-1, -1, -1, 0, -1, -1, -1,-1, 1, 8, -1, 9, 2,-11, -1, -1)); __m128i row0 = _mm_or_si128(row0_A, row0_B); row0 = _mm_insert_epi8(row0, _mm_extract_epi8(C, 0), 10); // row1 = [A12 B3 B10 C1 C8 D0 C9 C2 B11 B4 A13 A6 A7 A14 B5 B12] const __m128i row1_A = _mm_shuffle_epi8(A, _mm_setr_epi8(12, -1, -1, -1, -1, -1, -1, -1, -1, -1, 13, 6, 7, 14, -1, -1)); const __m128i row1_B = _mm_shuffle_epi8(B, _mm_setr_epi8(-1, 3, 10, -1, -1, -1, -1, -1, 11, 4, -1, -1, -1, -1, 5, 12)); const __m128i row1_C = _mm_shuffle_epi8(C, _mm_setr_epi8(-1, -1, -1, 1, 8, -1, 9, 2, -1, -1, -1, -1, -1, -1, -1, -1)); __m128i row1 = _mm_or_si128(row1_A, _mm_or_si128(row1_B, row1_C)); row1 = _mm_insert_epi8(row1, _mm_extract_epi8(D, 0), 5); // row2 = [C3 C10 D1 D8 D9 D2 C11 C4 B13 B6 A15 B7 B14 C5 C12 D3] const __m128i row2_B = _mm_shuffle_epi8(B, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, 13, 6, -1, 7, 14, -1, -1, -1)); const __m128i row2_C = _mm_shuffle_epi8(C, _mm_setr_epi8(3, 10, -1, -1, -1, -1, 11, 4, -1, -1, -1, -1, -1, 5, 12, -1)); const __m128i row2_D = _mm_shuffle_epi8(D, _mm_setr_epi8(-1, -1, 1, 8, 9, 2, -1, -1, -1, -1, -1, -1, -1, -1, -1, 3)); __m128i row2 = _mm_or_si128(row2_B, _mm_or_si128(row2_C, row2_D)); row2 = _mm_insert_epi8(row2, _mm_extract_epi8(A, 15), 10); // row3 = D10 D11 D4 C13 C6 B15 C7 C14 D5 D12 D13 D6 C15 D7 D14 D15 const __m128i row3_C = _mm_shuffle_epi8(C, _mm_setr_epi8(-1, -1, -1, 13, 6, -1, 7, 14, -1, -1, -1, -1, 15, -1, -1, -1)); const __m128i row3_D = _mm_shuffle_epi8(D, _mm_setr_epi8(10, 11, 4, -1, -1, -1, -1, -1, 5, 12, 13, 6, -1, 7, 14, 15)); __m128i row3 = _mm_or_si128(row3_C, row3_D); row3 = _mm_insert_epi8(row3, _mm_extract_epi8(B, 15), 5); _mm_storeu_si128((__m128i*)(out + 0*16), row0); _mm_storeu_si128((__m128i*)(out + 1*16), row1); _mm_storeu_si128((__m128i*)(out + 2*16), row2); _mm_storeu_si128((__m128i*)(out + 3*16), row3); }
Number of instructions:
- 4 loads;
- 10 shuffles;
- 4 insert-load-byte;
- 6 bit-or;
- 4 stores.
AVX512BW implementation
The AVX512BW variant of pshufb instruction (vpshufb, _mm512_shuffle_epi8) works on 128-bit lanes. Thus, in this implementation we perform all in-lane shuffles (for pairs of rows) using single vpshufb; moreover, we get rid of extract/insert operations.
In order to do this the 128-bit lanes have to be populated after single load.
Sample implementation:
void jpeg_zigzag_avx512bw(const uint8_t* in, uint8_t* out) { const __m512i v = _mm512_loadu_si512((const __m512i*)in); // populate lanes -- each lane represents pair of output rows #if 1 // as proposed by InstLatX64 const __m512i A = _mm512_broadcast_i32x4(_mm_loadu_si128((const __m128i*)(in + 0 * 16))); const __m512i B = _mm512_broadcast_i32x4(_mm_loadu_si128((const __m128i*)(in + 1 * 16))); const __m512i C = _mm512_broadcast_i32x4(_mm_loadu_si128((const __m128i*)(in + 2 * 16))); const __m512i D = _mm512_broadcast_i32x4(_mm_loadu_si128((const __m128i*)(in + 3 * 16))); #else const __m512i v = _mm512_loadu_si512((const __m512i*)in); const __m512i A = _mm512_permutexvar_epi32( _mm512_setr_epi32(0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3), v); const __m512i B = _mm512_permutexvar_epi32( _mm512_setr_epi32(4, 5, 6, 7, 4, 5, 6, 7, 4, 5, 6, 7, 4, 5, 6, 7), v); const __m512i C = _mm512_permutexvar_epi32( _mm512_setr_epi32(8, 9, 10, 11, 8, 9, 10, 11, 8, 9, 10, 11, 8, 9, 10, 11), v); const __m512i D = _mm512_permutexvar_epi32( _mm512_setr_epi32(12, 13, 14, 15, 12, 13, 14, 15, 12, 13, 14, 15, 12, 13, 14, 15), v); #endif // perform shuffling within lanes static int8_t shuffle_A[64] __attribute__((aligned(64))) = { 0, 1, 8, -1, 9, 2, 3, 10, -1, -1, -1, -1, -1, 11, 4, 5, 12, -1, -1, -1, -1, -1, -1, -1, -1, -1, 13, 6, 7, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 }; static int8_t shuffle_B[64] __attribute__((aligned(64))) = { -1, -1, -1, 0, -1, -1, -1, -1, 1, 8, -1, 9, 2, -1, -1, -1, -1, 3, 10, -1, -1, -1, -1, -1, 11, 4, -1, -1, -1, -1, 5, 12, -1, -1, -1, -1, -1, -1, -1, -1, 13, 6, -1, 7, 14, -1, -1, -1, -1, -1, -1, -1, -1, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 }; static int8_t shuffle_C[64] __attribute__((aligned(64))) = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, -1, -1, -1, -1, -1, -1, -1, -1, 1, 8, -1, 9, 2, -1, -1, -1, -1, -1, -1, -1, -1, 3, 10, -1, -1, -1, -1, 11, 4, -1, -1, -1, -1, -1, 5, 12, -1, -1, -1, -1, 13, 6, -1, 7, 14, -1, -1, -1, -1, 15, -1, -1, -1 }; static int8_t shuffle_D[64] __attribute__((aligned(64))) = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 8, 9, 2, -1, -1, -1, -1, -1, -1, -1, -1, -1, 3, 10, 11, 4, -1, -1, -1, -1, -1, 5, 12, 13, 6, -1, 7, 14, 15 }; const __m512i shufA = _mm512_shuffle_epi8(A, _mm512_load_si512((const __m512i*)shuffle_A)); const __m512i shufB = _mm512_shuffle_epi8(B, _mm512_load_si512((const __m512i*)shuffle_B)); const __m512i shufC = _mm512_shuffle_epi8(C, _mm512_load_si512((const __m512i*)shuffle_C)); const __m512i shufD = _mm512_shuffle_epi8(D, _mm512_load_si512((const __m512i*)shuffle_D)); // merge all shufX vectors const uint8_t OR_ALL = 0xfe; const __m512i res = _mm512_or_si512(shufD, _mm512_ternarylogic_epi32(shufA, shufB, shufC, OR_ALL)); _mm512_storeu_si512((__m512i*)out, res); }
Number of instructions:
- 5 512-bit loads;
- 4 128-bit loads;
- 4 broadcasts;
- 4 in-lane shuffles;
- 1 ternary logic;
- 1 bit-or;
- 1 store.
The initial variant used cross-lane shuffles within registers (vpermd, _mm512_permutexvar_epi32). InstLatX64 proposed to use vbroadcasti32x4 (_mm512_broadcast_i32x4) which broadcasts 128-bit lanes to lanes. While vpermd can be dispatched only on port 5, broadcasts can be issued to ports 2 and 3. As a result average cycles dropped from 15 to 11 (1.35 x times faster).
Instead of explicit merging of partial results, it is possible to use masked invocation of vpshufb (_mm512_mask_shuffle_epi8). The tail of above procedure is changed into.
// ... __m512i result = _mm512_shuffle_epi8(A, _mm512_load_si512((const __m512i*)shuffle_A)); result = _mm512_mask_shuffle_epi8(result, 0x00201b00c3061b08lu, B, _mm512_load_si512((const __m512i*)shuffle_B)); result = _mm512_mask_shuffle_epi8(result, 0x10d860c300d80400lu, C, _mm512_load_si512((const __m512i*)shuffle_C)); result = _mm512_mask_shuffle_epi8(result, 0xef07803c00200000lu, D, _mm512_load_si512((const __m512i*)shuffle_D)); _mm512_storeu_si512((__m512i*)out, result);
Number of instructions:
- 5 loads;
- 4 cross-lane shuffles;
- 4 in-lane shuffles;
- 1 store.
AVX512BW implementation — second variant
AVX512BW supports also cross-lane permutations, but the instruction vpermw (_mm512_permutexvar_epi16) works on 16-bit values. Thus, we can only move pairs of pixels.
The idea is to use vpermw to move required bytes into given 128-bit lanes, and then use pshufb to precisely place individual bytes within lanes. Due to the required order of bytes single invocation of vpermw is not sufficient; it must be done in two steps.
Lane 0 (rows 1 & 2) contains following bytes (sorted):
0, 1, 2, 3, 4, 5, 8, 9, 10, 11, 16, 17, 18, 24, 25, 32
Lane 1 (rows 2 & 3):
6, 7, 12, 13, 14, 19, 20, 21, 26, 27, 28, 33, 34, 40, 41, 48
Lane 2 (rows 4 & 5):
15, 22, 23, 29, 30, 35, 36, 37, 42, 43, 44, 49, 50, 51, 56, 57
Lane 3 (rows 6 & 7):
31, 38, 39, 45, 46, 47, 52, 53, 54, 55, 58, 59, 60, 61, 62, 63
In the first step of transformation lanes are populated with following pair of bytes (colors match registers A, B, C and D).
lane 0 = [ 0, 1][ 2, 3][ 4, 5][ 8, 9][10,11][16,17][18,19][24,25] lane 1 = [ 6, 7][12,13][14,15][20,21][26,27][28,29][32,33][34,35] lane 2 = [22,23][30,31][36,37][42,43][44,45][48,49][50,51][56,57] lane 3 = [38,39][46,47][52,53][54,55][58,59][60,61][62,63][62,62]
Please note that there are a few extra values [marked with black] -- lane 0: 19; lane 1: 15, 29; lane 2: 31, 45, 48.
Following values are not present in lanes after the first shuffle:
- lane 0: 32;
- lane 1: 19, 34, 40, 41, 48;
- lane 2: 15, 29, 35;
- lane 3: 31, 45.
This is the reason why the second invocation of vpermw is needed. Following diagram shows layout of byte pairs in the second step:
lane 0 = [32,33][32,33][32,33][32,33][32,33][32,33][32,33][32,33] lane 1 = [18,19][34,35][40,41][48,49][48,49][48,49][48,49][48,49] lane 2 = [14,15][28,29][34,35][34,35][34,35][34,35][34,35][34,35] lane 3 = [30,31][44,45][44,45][44,45][44,45][44,45][44,45][44,45]
The last, third step consists two vpshufb invocation that moves bytes within lanes. These shuffled vectors are or'ed together and the result is stored.
Sample implementation is shown below. The repository has got a python script that calculates all arguments for shuffles (it's pretty boring and error prone).
void jpeg_zigzag_avx512bw_permute16(const uint8_t* in, uint8_t* out) { const __m512i v = _mm512_loadu_si512((const __m512i*)in); // crosslane 16-bit shuffle #1 const int16_t crosslane_shuffle1[32] __attribute__((aligned(64))) = { 0, 1, 2, 4, 5, 8, 9, 12, 3, 6, 7, 10, 13, 14, 16, 17, 11, 15, 18, 21, 22, 24, 25, 28, 19, 23, 26, 27, 29, 30, 31, 31 }; const __m512i shuf1 = _mm512_permutexvar_epi16(_mm512_load_si512((__m512i*)crosslane_shuffle1), v); // in-lane 8-bit shuffle #1 const int8_t inlane_shuffle1[64] __attribute__((aligned(64))) = { /* lane 0 */ 0, 1, 6, 10, 7, 2, 3, 8, 11, 14, -1, 15, 12, 9, 4, 5, /* lane 1 */ 2, -1, 8, 13, -1, -1, -1, 14, 9, 6, 3, 0, 1, 4, 7, 10, /* lane 2 */ -1, 6, 11, 14, 15, 12, 7, 4, -1, 0, -1, 1, 2, 5, 8, 13, /* lane 3 */ 8, 9, 4, -1, 0, -1, 1, 2, 5, 10, 11, 6, 3, 7, 12, 13 }; const __m512i t0 = _mm512_shuffle_epi8(shuf1, _mm512_load_si512(inlane_shuffle1)); // crosslane 16-bit shuffle #2 const int16_t crosslane_shuffle2[32] __attribute__((aligned(64))) = { /* lane 0*/ 16, 16, 16, 16, 16, 16, 16, 16, /* lane 1*/ 9, 17, 20, 24, 24, 24, 24, 24, /* lane 2*/ 7, 14, 17, 17, 17, 17, 17, 17, /* lane 3*/ 15, 22, 22, 22, 22, 22, 22, 22 }; const __m512i shuf2 = _mm512_permutexvar_epi16(_mm512_load_si512((__m512i*)crosslane_shuffle2), v); // in-lane 8-bit shuffle #2 const int8_t inlane_shuffle2[64] __attribute__((aligned(64))) = { /* lane 0 */ -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, -1, -1, -1, -1, -1, /* lane 1 */ -1, 1, -1, -1, 4, 6, 5, 2, -1, -1, -1, -1, -1, -1, -1, -1, /* lane 2 */ 5, -1, -1, -1, -1, -1, -1, -1, 3, -1, 1, -1, -1, -1, -1, -1, /* lane 3 */ -1, -1, -1, 3, -1, 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 }; const __m512i t1 = _mm512_shuffle_epi8(shuf2, _mm512_load_si512(inlane_shuffle2)); const __m512i res = _mm512_or_si512(t0, t1); _mm512_storeu_si512((__m512i*)out, res); }
Number of instructions:
- 5 loads;
- 2 cross-lane shuffles;
- 2 in-lane shuffles;
- 1 bit-or;
- 1 store;
AVX512VBMI implementation
The whole transformation is done by single instruction vpermb (_mm512_permutexvar_epi8). The instruction shuffles bytes across lanes.
(zigzag_shuffle is defined with scalar code above)
void jpeg_zigzag_avx512vbmi(const uint8_t* in, uint8_t* out) { const __m512i t0 = _mm512_loadu_si512((const __m512i*)in); const __m512i t1 = _mm512_loadu_si512((const __m512i*)zigzag_shuffle); const __m512i t2 = _mm512_permutexvar_epi8(t1, t0); _mm512_storeu_si512((__m512i*)out, t2); }
Performance evaluation
The benchmark program runs zigzag transformation 1,000,000 times. I run it a few times and noted the minimum values.
| name | comments |
|---|---|
| scalar | |
| SSE | |
| AVX512BW | |
| AVX512BW (masks) | AVX512BW that use mask stores rather bit-level merging |
| AVX512BW (perm16) |
The program was compiled with GCC 7.3.0 and run on Skylake Core i7-6700 CPU @ 3.40GHz.
| procedure | best [cycles] | average [cycles] |
|---|---|---|
| scalar | 98.000 | 103.069 |
| SSE | 16.000 | 26.614 |
| AVX512BW | 4.000 | 11.002 |
| AVX512BW (masks) | 10.000 | 16.732 |
| AVX512BW (perm16) | 16.000 | 24.588 |
AVX512BW code is almost two times faster than SSE.
Shuffling 16-bit array
Scalar implementation
The scalar implementation is basically 8-bit scalar with different types used.
uint16_t zigzag_shuffle[64] = { 0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5, 12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28, 35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51, 58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63 }; void jpeg_zigzag_scalar(const uint16_t* in, uint16_t* out) { for (int i=0; i < 64; i++) { unsigned index = zigzag_shuffle[i]; out[i] = in[index]; } }
Assembly code is:
jpeg_zigzag_scalar: leaq zigzag_shuffle(%rip), %rcx xorl %eax, %eax .L2: movzwl (%rcx,%rax), %edx movzwl (%rdi,%rdx,2), %edx movw %dx, (%rsi,%rax) addq $2, %rax cmpq $128, %rax jne .L2 rep ret
SSE implementation
When 16-bit words are stored in an array, then single SSE register holds exactly one row of 8 x 8 pixels block.
We can use the same techniques as in 8-bit arrays handling. We can shuffle an input register and merge it with the destination register (with pair PSHUFB/POR); we just have to keep in mind that PSHUFB must move whole 16-bit blocks.
There are two variants of SSE procedure:
- one that uses only shuffle instructions;
- simplified one; in same cases there's need to copy only single item from one register to another, then a pair of instruction PEXTRACTW and PINSERTW is suitable.
Please refer to sources for full SSE implementations; they are auto-generated, thus there is no much sense to copy them here.
Shuffle-only
Below is a summary which operations are required to build output rows:
- row 0 — 3 x shuffle, 2 x bit-or;
- row 1 — 5 x shuffle, 4 x bit-or;
- row 2 — 6 x shuffle, 5 x bit-or;
- row 3 — 4 x shuffle, 3 x bit-or;
- row 4 — 4 x shuffle, 3 x bit-or;
- row 5 — 6 x shuffle, 5 x bit-or;
- row 6 — 5 x shuffle, 4 x bit-or;
- row 7 — 3 x shuffle, 2 x bit-or.
Total number of instructions:
- 8 loads;
- 36 shuffles;
- 28 bit-or;
- 8 stores.
Shuffle with insert/extract
Below is a summary which operations are required to build output rows:
- row 0 — 2 x shuffle, 1 x bit-or, 1 x insert-load-word;
- row 1 — 3 x shuffle, 2 x bit-or, 2 x insert-load-word;
- row 2 — 2 x shuffle, 1 x bit-or, 4 x insert-load-word;
- row 3 — 4 x shuffle, 3 x bit-or;
- row 4 — 4 x shuffle, 3 x bit-or;
- row 5 — 2 x shuffle, 1 x bit-or, 4 x insert-load-word;
- row 6 — 3 x shuffle, 2 x bit-or, 2 x insert-load-word;
- row 7 — 2 x shuffle, 1 x bit-or, 1 x insert-load-word.
Number of instructions:
- 8 loads;
- 22 shuffles;
- 14 insert-load-word;
- 14 bit-or;
- 8 stores.
AVX512F implementation
In AVX512 code the whole 8 x 8 pixels table fits into two registers.
Although AVX512F lacks of byte- or word-level operation, we still can move pairs of pixels across register lanes using VPERMD instruction (_mm512_permutexvar_epi32). Then, there are basically three cases we must handle:
The lower or higher word of the shuffled pair matches exactly the target position. Then only bit-and is needed to mask out another helve.
// a. move pairs around using 'shuffle' pattern const __m128i permuted = _mm512_permutex2var_epi16(shuffle, register); // b. row = row | (permuted & mask) row = _mm512_ternarylogic_epi32(row, permuted, mask, 0xf8);
The lower word of the pair must be placed in higher word of target register. Then we need shift left the permuted vector by 16 bits. Note that unlike VPSHUFB, VPERMD does not zero target elements with a special index value. Thus an explicit bit-and is needed.
// a. move pairs around using 'shuffle' pattern const __m128i permuted = _mm512_permutex2var_epi16(shuffle, register); // b. shift lower word to higher word's position const __m128i shifted = _mm512_slli_epi32(permuted, 16); // c. row = row | (shifted & mask) row = _mm512_ternarylogic_epi32(row, shifted, mask, 0xf8);
Likewise, when higher word of the pair must be place in the lower word of target register, then shift left by 16 bits is invoked.
// a. move pairs around using 'shuffle' pattern const __m128i permuted = _mm512_permutex2var_epi16(shuffle, register); // b. shift higher word to lower word's position const __m128i shifted = _mm512_srli_epi32(permuted, 16); // c. row = row | (shifted & mask) row = _mm512_ternarylogic_epi32(row, shifted, mask, 0xf8);
The vectors shuffle and mask that are used in the above cases are compile-time constants.
The code for AVX512 was also auto-generated, please refer to sources for details. Below is the number of instructions:
- 16 x shuffle,
- 16 x ternary logic,
- 4 x shift right,
- 4 x shift left.
Implementation note
Similarly to other approaches, there are cases where just a single item from a source register has to be copied to the destination register. In case of SSE and AVX2 code we can use then specialized instructions for extract/insert 8-bit/16-bit items from a register.
AVX512F doesn't have such instructions, but copying 16-bit values is still doable. Below is a pattern:
const __m128i src = _mm512_extracti32x4_epi32(X, source_lane_index); const __m128i trg = _mm512_extracti32x4_epi32(Y, targer_lane_index); const uint16_t word = _mm_extract_epi16(src, source_word_index); const __m128i mod = _mm_insert_epi16(trg, word, target_word_index); Y = _mm512_inserti32x4(Y, mod, target_lane_index);
As we see, it is pretty complicated. The code consist of five instruction, while the generic algorithm compiles to three or four. The experiment results clearly show that code uses this approach is slower.
AVX512BW implementation
AVX512BW provides instruction VPERM2I (_mm512_permutex2var_epi16) that does cross-lane shuffling from two AVX512 registers. Since the whole 16-bit array fits into two registers we need to execute VPERM2I twice.
Implementation is straightforward.
void jpeg_zigzag_avx512bw(const uint16_t* in, uint16_t* out) { const __m512i A = _mm512_loadu_si512((const __m512i*)(in + 0*32)); const __m512i B = _mm512_loadu_si512((const __m512i*)(in + 1*32)); // note: zigzag_shuffle refers here to uint16_t array const __m512i shuf0 = _mm512_loadu_si512((const __m512i*)(zigzag_shuffle + 0*32)); const __m512i res0 = _mm512_permutex2var_epi16(A, shuf0, B); const __m512i shuf1 = _mm512_loadu_si512((const __m512i*)(zigzag_shuffle + 1*32)); const __m512i res1 = _mm512_permutex2var_epi16(A, shuf1, B); _mm512_storeu_si512((__m512i*)(out + 0*32), res0); _mm512_storeu_si512((__m512i*)(out + 1*32), res1); }
Performance evaluation
The test program benchmark_avx512bw was run five times and minimum times were noted. In single run each procedure is invoked 1,000,000 times.
| name | comments |
|---|---|
| scalar | |
| scalar (unrolled) | scalar unrolled 4 times |
| SSE | shuffle-only variant |
| SSE (copy single) | shuffle with insert/extract |
| AVX512F | shuffle-only variant |
| AVX512F (copy single) | shuffle with insert/extract emulation |
| AVX512BW |
| procedure | best [cycles] | average [cycles] | speedup | |
|---|---|---|---|---|
| scalar | 109.000 | 113.814 | 1.00 | █████ |
| scalar (unrolled) | 94.000 | 98.745 | 1.15 | █████▊ |
| SSE | 52.000 | 59.906 | 1.90 | █████████▍ |
| SSE (copy single) | 70.000 | 80.275 | 1.42 | ███████ |
| AVX512F | 34.000 | 42.295 | 2.69 | █████████████▍ |
| AVX512F (copy single) | 46.000 | 54.455 | 2.09 | ██████████▍ |
| AVX512BW | 8.000 | 14.453 | 7.87 | ███████████████████████████████████████▎ |
Source code
Source code is available on github.
Changelog
- 2018-11-04 — added 16bit-array shuffling
- 2018-05-15 — better broadcasting code in AVX512BW by InstLatX64
- 2018-05-14 — another AVX512BW variant, AVX512BW code which uses masked writes