Speedup reversing table of bytes
| Author: | Wojciech Muła |
|---|---|
| Added on: | 2010-05-01 |
In-place reversing is performed by following algorithm:
// n - table size
int i = 0; // index1
int j = n - 1; // index2
int c = n/2; // counter
int x, y;
while (c--)
x = table[i];
y = table[j];
table[i] = y;
table[j] = x;
i++;
j--;
c--;
}
We can use some CPU-specific instruction to speedup the algorithm.
- 486 processors have BSWAP instruction that swaps four bytes (quick conversion between big-/little-endian);
- SSE2 extension has PSHUFD that calculate any combination of dwords in an xmm register, likewise PSHUFLW and PSHUFHW calculate combinations of words;
- SSSE3 extension has PSHUFB that calculates any combination of 16 bytes from an xmm register.
Program can load a part of table into registers, then swap bytes in register using one or more instructions and then store register's content at new position. If the size of a table is not multiply of register size, then few bytes in the middle of a table have to be swapped using default algorithm.
Modified algorithm outline:
// n - table size
// k - register size - k=4 for BSWAP and k=16 for PSHUFB
int i = 0; // index1
int j = n - k - 1; // index2 !!!
int c = n/(2*k); // counter !!!
register char x[k], y[k]; // hardware registers
while (c--)
x = table[i]; // load k bytes
y = table[j]; // ...
hardware_swap(x); // reverse these bytes
hardware_swap(y); // ...
table[i] = y; // store k bytes
table[j] = x; // ..
i += k;
j -= k;
c--;
}
if (n % (2*k) != 0)
swap rest byte-by-byte
Function hardware_swap(x) is equivalent to single instruction: BSWAP reg or PSHUFB xmm, const; SSE2 code requires more instructions:
movaps %xmm0, %xmm1 psrlw $8, %xmm0 psllw $8, %xmm1 por %xmm1, %xmm0 ; swap adjacent bytes pshufd $0x4e, %xmm0, %xmm0 ; swap order of dwords pshuflw $0x1b, %xmm0, %xmm0 ; swap order of words in lower pshufhw $0x1b, %xmm0, %xmm0 ; .. and higher half of register
Test program contains several procedures that implement the modified algorithm:
- swap_tab_asm (alias x86) — asm implementation of default algorithm (reference);
- swap_tab_bswap (bswap) — modified algorithm: one bswap (8 bytes per iteration)
- swap_tab_bswap_unrolled (bswap2) — modified algorithm: two bswap (16 bytes per iteration)
- swap_tab_sse (sse) — modified algorithm: one SSE swap (32 bytes per iteration)
- swap_tab_sse_unrolled (sse2) — modified algorithm: two SSE swaps (64 bytes per iteration)
- swap_tab_pshufb (pshuf) — modified algorithm: one PSHUFB (32 bytes per iteration)
- swap_tab_pshufb_unrolled (pshuf2) — modified algorithm: two PSHUFB (64 bytes per iteration)
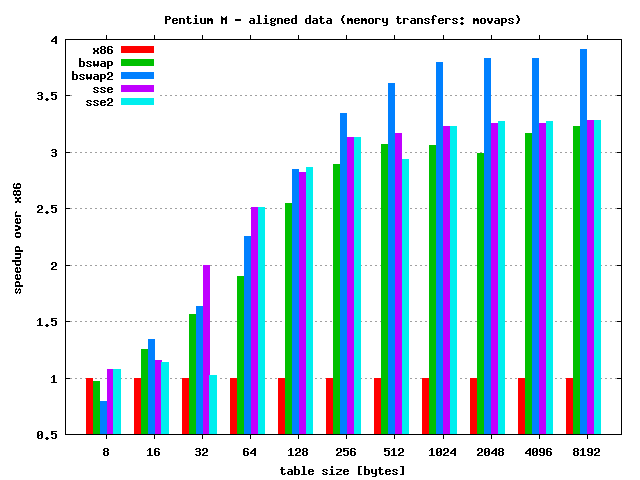
Important note: SSE implementations use safe MOVUPS instruction for transfers data from/to memory. This instruction is much slower than MOVAPS even if accessing aligned data!
Tests
Two scenarios of test were considered:
- The table size is hardware friendly, i.e. is multiply of implementation
base step; also address of table is aligned:
- all procedures use MOVUPS,
- all procedures use MOVAPS.
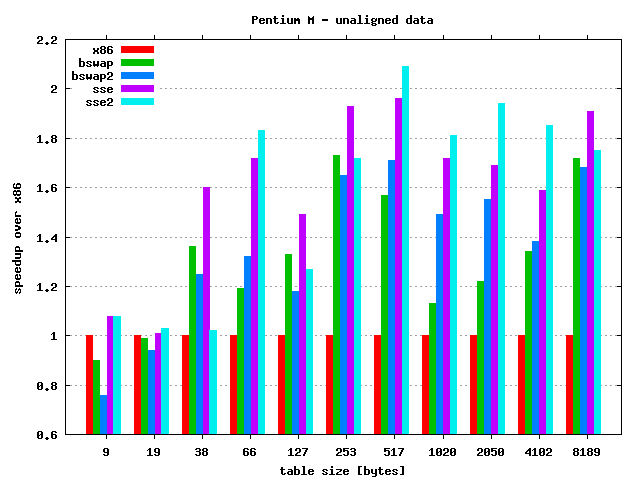
- The size is not hardware friendly and address is not aligned.
Procedures were tested on following computers:
- recent Core 2 Due E8200,
- quite old Pentium M (instruction PSHUFB not available).
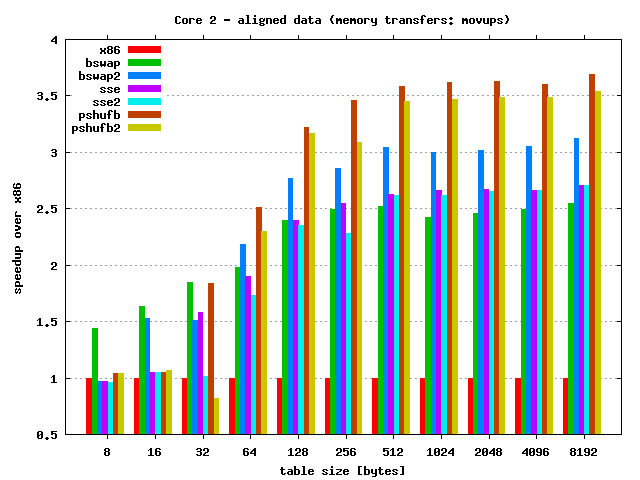
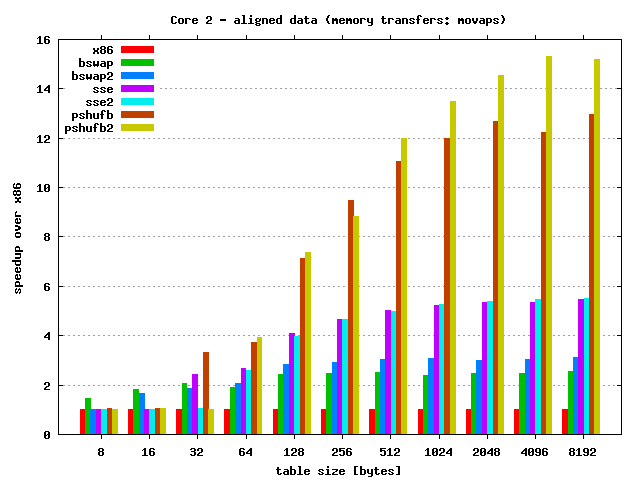
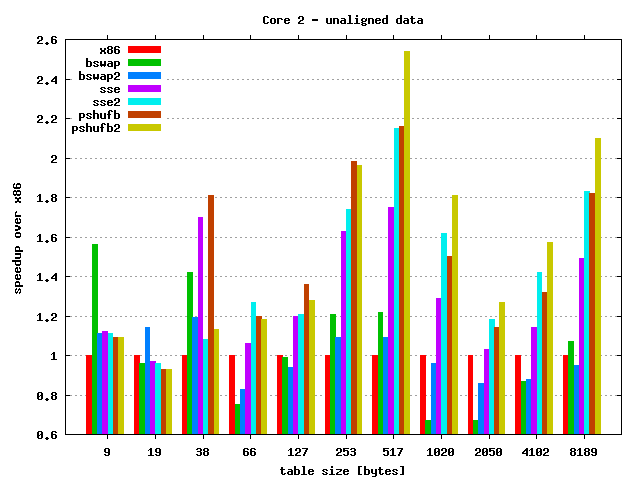
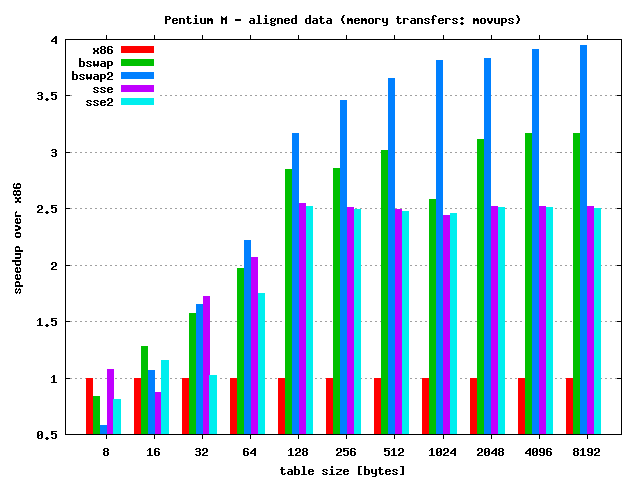
Quick results discussion:
- As always speedup depends on the table size — for larger tables
speedup is also larger. Max speedup:
- Core 2:
- 15.5 times — PSHUFB unrolled & MOVAPS
- 3.5 times — PSHUFB & MOVUPS
- Pentium M:
- 4 times — BSWAP unrolled
- Core 2:
- Unaligned memory access kills performance — results clearly shows this behaviour.